



Machine learning model training
The models are trained in the cloud service. Due to historical data analysis Creatio determines certain patterns that may further be used for predictions. The data used for model training is not saved in the cloud service. Instead, the cloud service is used to store the prediction patterns. Increasing the volume of historical data increases the accuracy of predictions. Therefore, all models must be retrained regularly.
Note
Predictive analytics in Creatio enables you to train models on collections containing up to 75,000 historical records. If a collection contains more than 75,000 records, the service will randomly select 75,000 records from the collection to train a machine learning model. To achieve the quality metric lower limit of 50%, it is recommended to use at least 20,000 historical records for training models that perform text data analysis and at least 1,000 historical records for training models that perform numeric data analysis.
The training progress bar on the machine learning model page enables you to track the current training stage of a model (Fig. 1).
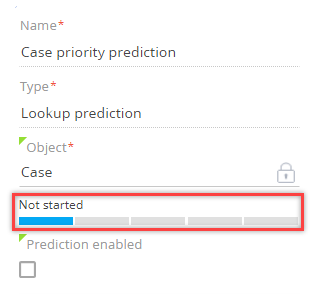
Once the model is successfully trained, a machine learning model instance is created and activated automatically. Retraining models and saving new instances occurs automatically in the background mode. Retraining frequency is configured in the [ML models] section.
The list of factors that affect the evaluation metric or the quality of a trained ML model (aka “predictors”) are displayed on the [Training] tab of the model, at the top of the page (Fig. 2). The numbers show how strongly each factor will affect the prediction result. The factors will be displayed once the model training is complete.
Fig. 2 Factors that influence the predictive score
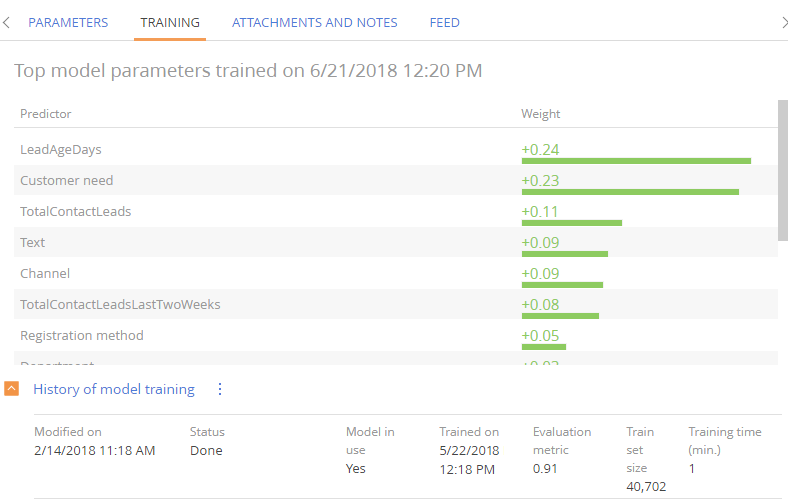
When setting up prediction models, the analysts can use this data to fine-tune the model parameters.
See also
•Basic predictive analysis glossary
•Numeric field value prediction