









Machine learning service
Glossary Item Box

Introduction
The machine learning (lookup value prediction) service uses statistical analysis methods for machine learning based on historical data. For example, a history of customer communications with customer support is considered historical data in bpm’online. The message text, the date and the account category are used. The result is the [Responsible Group] field.
Bpm’online interaction with the prediction service
There are two stages of model processing in bpm’online: training and prediction.
Prediction model is the algorithm which builds predictions and enables the system to automatically make decisions based on historical data.
Training
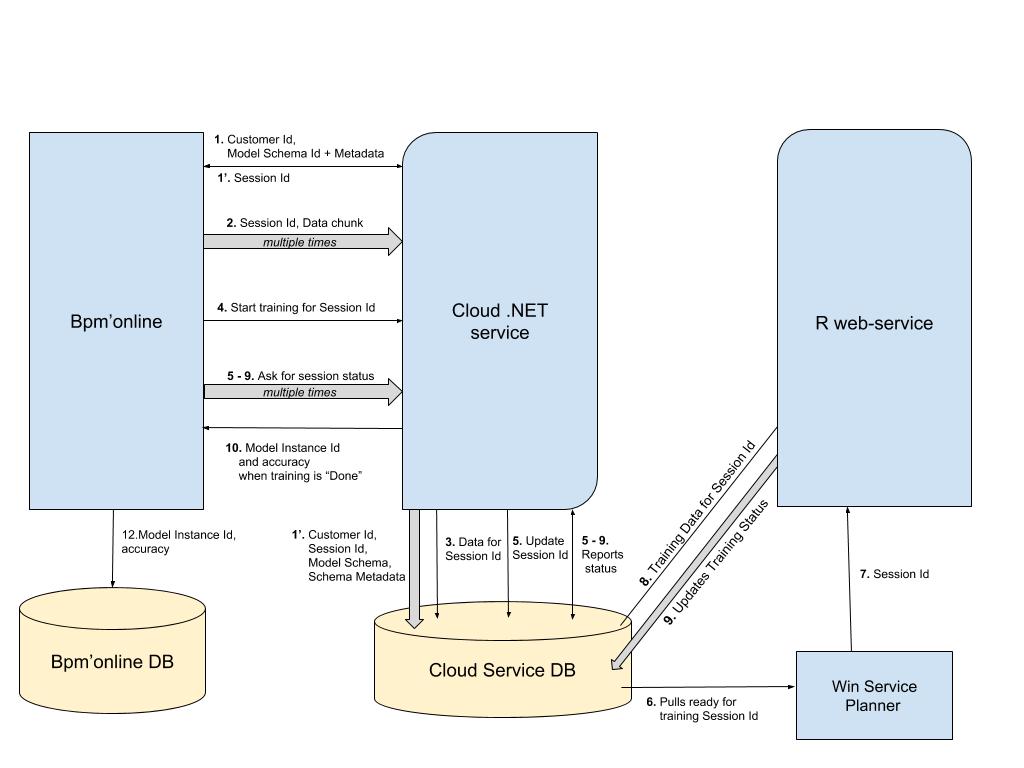
The service is “trained” at this stage (Fig. 1). Main training steps:
- Establishing a session for data transfer and training.
- Sequentially selecting a portion of data for the model and uploading it to the service.
- Requesting to include a model a training queue.
- Training engine processes the queue for model training, trains the model and saves its parameters to the local database.
- Bpm'online occasionally queries the service to get the model status.
- Once the model status is set to Done, the model is ready for prediction.
Fig. 1. Bpm’online interaction with the prediction service on the training stage
Prediction
The prediction task is performed through a call to the cloud service, indicating the Id of the model instance and the data for the prediction. The result of the service operation is a set of values with prediction probabilities, which is stored in bpm'online in the MLPrediction table.
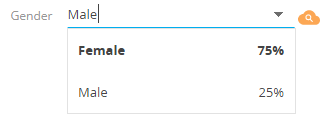
If there is a prediction in the MLPrediction table for a particular entity record, the predicted values for the field are automatically displayed on the edit page (Fig. 2).
Fig. 2. Displaying prediction data
Bpm'online settings and data types for working with the prediction service
Bpm'online setup
The following data is provided for working with the prediction service in bpm'online.
- The CloudServicesAPIKey system setting authenticates the bpm'online instance in cloud services.
- The record in the [ML problem types] (MLProblemTypes) lookup with the populated [ServiceUrl] field is the address of the implemented prediction service.
- The model records in the [ML model] (MLModel) lookup that contain information about the selected data for the model, the training period, the current training status, etc. For each model, the MLProblemType field must contain a reference to the correct record of the [ML problem types] lookup.
- The MLModelTrainingPeriodMinutes system setting determines the frequency of model synchronization launch.
The MLModel lookup
The primary fields of MLModel lookup are given in Table 1.
Table 1. – Main MLModel lookup fields
| Field | Data type | Purpose |
|---|---|---|
| Name | String | Model name |
| ModelInstanceUId | Unique identifier | The identifier of the current model instance. |
| TrainedOn | Date/time | The date/time of instance training. |
| TriedToTrainOn | Date/time | The date/time of last training attempt. |
| TrainFrequency | Integer | Model retraining frequency (days). |
| MetaData | String |
Metadata with selection column types. Uses the following JSON format:
{
inputs: [
{
name: "Name of the field 1 in the data sample",
type: "Text",
isRequired: true
},
{
name: "Name of the field 2 in the data sample",
type: "Lookup"
},
//...
],
output: {
name: "Resulting field",
type: "Lookup",
displayName: "Name of the column to display"
}
}
In this code:
Column descriptions support the following attributes:
|
| TrainingSetQuery | String |
C#-expression of the training data selection. This expression should return the Terrasoft.Core.DB.Select class instance. For example: (Select)new Select(userConnection) .Column("Id") .Column("Symptoms") .Column("CreatedOn") .From("Case", "c") .OrderByDesc("c", "CreatedOn") ATTENTION Select the “Unique identifier” column type in the selection expression. This column should have the Id name. ATTENTION If the selection expression contains a column for sorting, then this column must be present in the resulting selection. You can find examples of queries in the "Creating data queries for the machine learning model” article. |
| RootSchemaUId | Unique identifier | A link to an object schema for which the prediction will be executed. |
| Status | String | The status of model processing (data transfer, training, ready for forecasting). |
| InstanceMetric | Number | A quality metric for the current model instance. |
| MetricThreshold | Number | Lowest threshold of model quality. |
| PredictionEnabled | Logical | A flag that includes the prediction for this model. |
| TrainSessionId | Unique identifier | Current training session. |
| MLProblemType | Unique identifier | Machine learning problem (defines the algorithm and service url for model training). |
A set of classes for training
MLModelTrainerJob: IJobExecutor, IMLModelTrainerJob – model synchronization task
Orchestrates model processing on the side of bpm’online by launching data transfer sessions, starting trainings, and also checking the status of the models processed by the service. Instances are launched by default by the task scheduler through the standard Execute method of the IJobExecutor interface.
Public methods:
IMLModelTrainerJob.RunTrainer() is a virtual method that encapsulates the synchronization logic. The base implementation of this method performs the following actions:
1. Selecting models for training – the records are selected from MLModel based on the following filter:
- The MetaData and TrainingSetQuery fields are populated.
- The Status field is not in the NotStarted, Done or Error state (or not populated at all).
- TrainFrequency is more than 0.
- The TrainFrequency days have passed since the last training date (TriedToTrainOn).
For each record of this selection, the data is sent to the service with the help of the predictive model trainer (see below).
2. Selecting previously trained models and updating their status (if necessary).
The data transfer session for the selection starts for each suitable model. The data is sent in packages of 1000 records during the session. For each model, the selection size is limited to 75,000 records.
MLModelTrainer: IMLModelTrainer – the trainer of the prediction model.
Responsible for the overall processing of a single model during the training stage. Communication with the service is provided through a proxy to a predictive service (see below).
Public methods:
IMLModelTrainer.StartTrainSession() – sets the training session for the model.
IMLModelTrainer.Upload Data() – transfers the data according to the model selection in packages of 1000 records. The selection is limited to 75,000 records.
IMLModelTrainer.BeginTraining() – indicates the completion of data transfer and informs the service about the need to put the model in the training queue.
IMLModelTrainer.UpdateModelState – requests the service for the current state of the model and updates the Status (if necessary).
If the training was successful (Status contains the Done value), the service returns the metadata for the trained instance, particularly the accuracy of the resulting instance. If the precision is greater than or equal to the lower threshold (MetricThreshold), the ID of the new instance is written in the ModelInstanceUId field.
MLServiceProxy: IMLServiceProxy – proxy to the prediction service
A wrapper class for http requests to a prediction service.
Public methods:
IMLServiceProxy.UploadData() – sends a data package for the training session.
MLServiceProxy.BeginTraining() – calls the service for setting up training in the queue
IMLServiceProxy.GetTrainingSessionInfo() – requests the current state from the service for the training session.
IMLServiceProxy.Classify(Guid modelInstanceUId, Dictionary<string, object> data) – calls the prediction service of the field value for a single set of field values for the previously trained model instance. In the Dictionary data parameter, the field name is passed as the key, which must match the name specified in the MetaData field of the model lookup. If the result is successful, the method returns a list of values with the ClassificationResult type.
Basic properties of the ClassificationResult type:
- Value – field value.
- Probability – the probability of a given value in the Array range. The sum of the probabilities for one list of results is close to 1 (values of about 0 can be omitted).
-
Significance - the level of importance of this prediction. This is a string enumeration with the following options:
- High - this field value has a distinct advantage over other values from the list. Only one element in the prediction list can have this level.
- Medium - the value of the field is close to several other high values in the list. For example, two values in the list have a probability of 0.41 and 0.39, and all the others are significantly smaller.
- None - irrelevant values with low probabilities.
Expanding the training model logic
The above chain of classes calls and creates instances of each other through the IOC of the Terrasoft.Core.Factories.ClassFactory container.
If you need to replace the logic of any component, you need to implement the appropriate interface. When you start the application, you must bind the interface in your own implementation.
Interfaces for logic expansion:
IMLModelTrainerJob – the implementation of this interface will enable you to change the set of models for training.
IMLModelTrainer – responsible for the logic of loading data for training and updating the status of models.
IMLServiceProxy - the implementation of this interface will enable yo to execute queries to arbitrary predictive services.
Auxiliary classes for forecasting
Auxiliary (utility) classes for forecasting enable you to implement two basic cases:
- Prediction at the time of creating or updating an entity record on the server.
- Prediction when the entity is changed on the edit page.
While predicting on the bpm'online server side, a business process is created that responds to the entity creation/change signal, reads a set of fields, and calls the prediction service. If you get the correct result, it stores the set of field values with probabilities in the MLClassificationResult table. If necessary, the business process records a separate value (for example, with the highest probability) in the corresponding field of the entity.
MLEntityPredictor
A utility class that helps to predict the value of a field based on a particular model (either one or several models) for a particular entity.
Some of the public methods include:
PredictEntityValueAndSaveResult(Guid modelId, Guid entityId) – based on the model Id and entity Id, performs predictions and records the results in the resulting entity field. Works with any machine learning task: classification, scoring, numeric field prediction.
ClassifyEntityValues(List<Guid> modelIds, Guid entityId) – based on the model (or list of several models created for the same object) Id and entity Id performs classification and returns the glossary, whose key is the model object, and the values are the predicted values.
MLPredictionSaver
The utility class that assists to save the prediction results in the bpm’online object.
Some of the public methods include:
SaveEntityPredictedValues(Guid schemaUId, Guid entityId, Dictionary<MLModelConfig, List<ClassificationResult>> predictedValues, Func<Entity, string, ClassificationResult, bool> onSetEntityValue) - saves the (MLEntityPredictor.ClassifyEntityValues) classification results in the bpm’online object. By default, it saves only the result, whose Significance equals to“High”. You can still override this behavior using the passed onSetEntityValue delegate. If the delegate returns false, the value will not be recorded in the bpm’online object.