Creatio trains the models in the cloud service. The model determines patterns it will use for predictions during the historical data analysis. Creatio does not save the model training data to the cloud service. The service only stores the prediction patterns.
The training record number
The predictive analysis service trains models on collections with up to 75,000 historical records. If there are more than 75,000 records in a collection, the service will select 75,000 records from the collection randomly.
For text data analysis training models, we recommend using at least 20,000 historical records to reach the lowest prediction quality threshold of 50%. For numeric data analysis training models, we recommend using at least 1,000 historical records to reach the same quality threshold.
Increasing the volume of historical data increases the prediction accuracy. As such, we recommend retraining all models regularly.
The model training status
Track the current model training status with the training progress bar on the ML model page (Fig. 1).
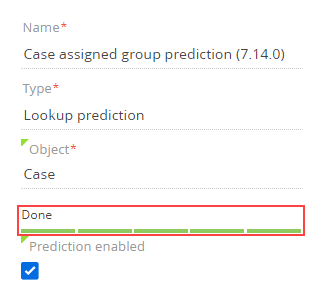
Once the model is successfully trained, Creatio will save a data prediction model instance and activate it automatically. Creatio retrains models and saves new instances in the background. Set up the retraining frequency in the ML models section.
Factors that influence the prediction
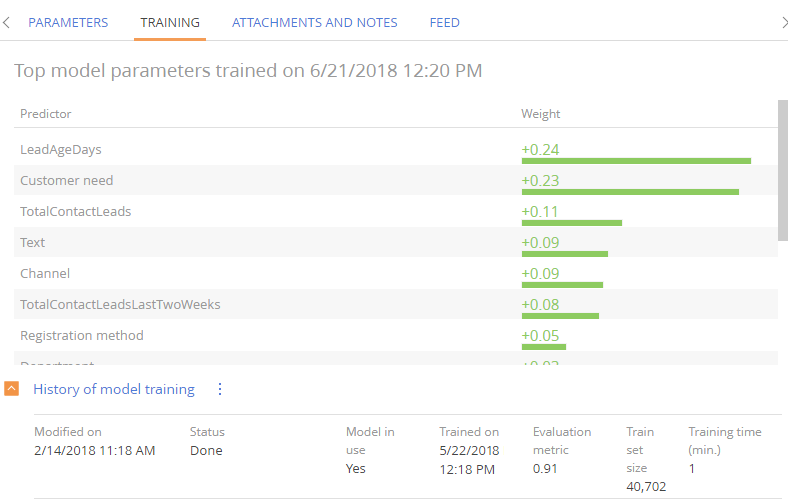
Find the list of factors that influence the prediction or the model training quality at the top of the Training tab (Fig. 2). The numbers show how strongly each factor influences the prediction result. The factors are displayed once the model training is complete.
Review TOP words and phrases that influence the prediction results (Fig. 3) on the Training tab after training a text data prediction model.
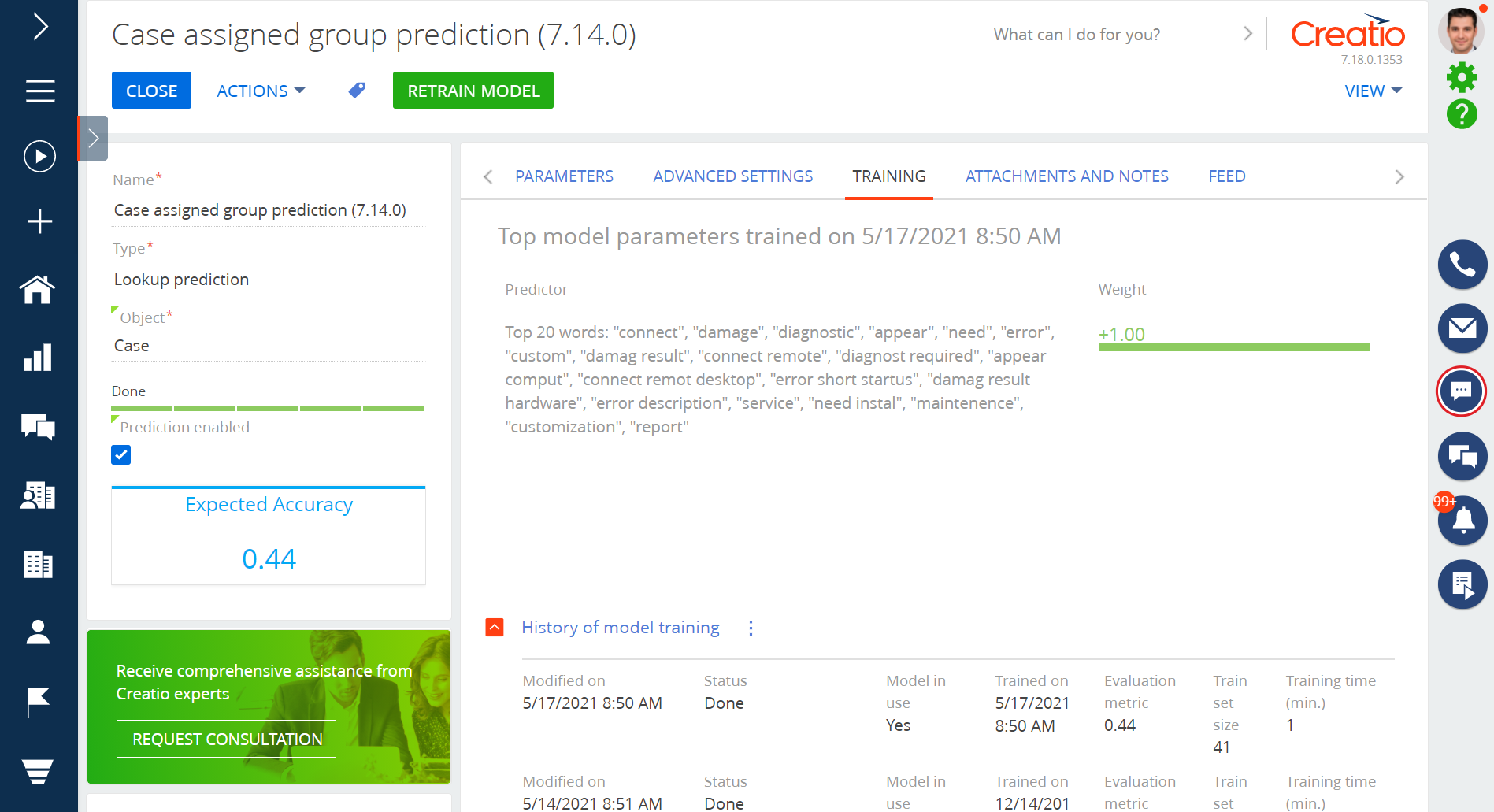
Use this data to analyze the model's prediction principles and results, as well as to debug its parameters if necessary.
Change the number of top words
By default, the ML service will select and use the top 20 words. To increase or decrease the number of top words for the training set, update the JSON string in your ML model's Query metadata for selecting additional training data field. For example, use the JSON object below to select the top 40 words:
Exclude words from the training set
There may be instances where the ML model considers frequent words as top words. That includes greetings, phone numbers, signatures, company names, or job positions. You can specify words that the ML model must ignore during training to prevent them from affecting the training results.
To exlude words from ML model training, update the JSON string in your ML model's Query metadata for selecting additional training data field. For example, use the JSON object below to select the top 10 words and ignore the words "local" and "entertain":