Enrich contact data from emails
Creatio helps to maintain the completeness and relevance of the customer base using the data enrichment feature. Data enrichment from emails is available in Creatio since version 7.10.0. The system scans emails and identifies information that can be used to enrich contact data.
Add the information of an account to Creatio from open sources in a few clicks, and enrich the account data using their social profiles.
The data enrichment is disabled by default. To enable data enrichment from correspondence and open sources, specify a cloud service key in the Enable enrichment of contacts from the incoming emails system setting (EnableEmailMining code).
The enrichment process
Receiving contact/account data from an email:
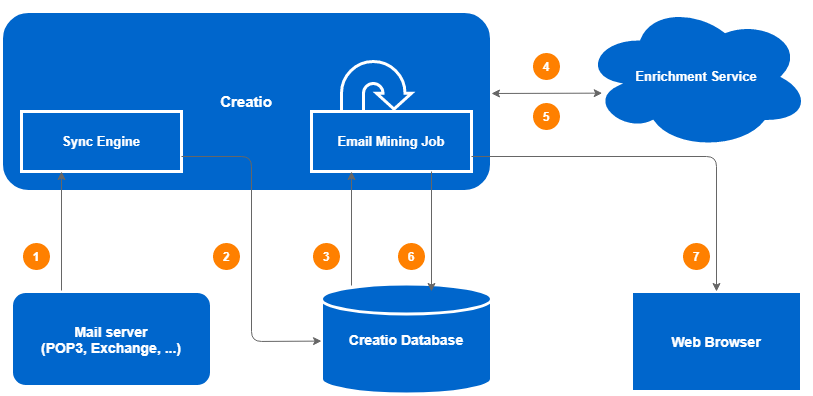
The main data enrichment stages:
-
The existing Sync Engine synchronization method connects to the mail server. The mail server sends new emails to the Sync Engine.
-
Sync Engine saves the received emails in the database as activities with the
Emailtype. -
The Creatio planner periodically performs a task that starts the
Email Mining Jobprocess. This process selects some of the last (by creation date) activities with theEmailtype that were not previously processed by it. From each activity record, the body of the email and its format (plain–text or html) are selected. -
The
Email Mining Jobprocess for each selected email sends an http request to theEnrichment Servicecloud service. -
Enrichment Serviceperforms the following actions:- selects a chain of individual emails (replies) from the email;
- selects a signature for each email (
signature); - separates the entity (
entity extraction) from the signature – contact (name, position), telephones, emails and web addresses, social networks, other means of communication, addresses, organization names.
Enrichment Servicereturns the gathered in the http–response as a specific structure in the JSON format.
-
The
Email Mining Jobprocess parses the structure received from the service and stores it in Creatio tables .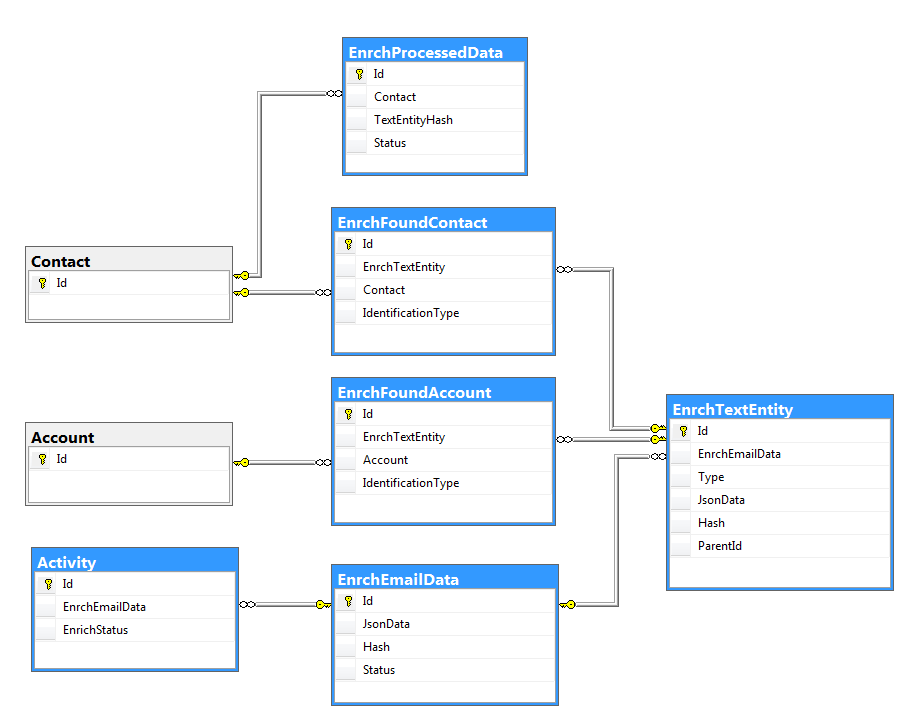
The main purpose of the tables :
EnrchTextEntity– stores information about one entity selected from an email. TheTypefield defines the type of this entity (contact, communication, address, organization, etc.). The data itself is stored in the JSON format in theJsonDatafield.EnrchEmailData– defines a set of information for enrichment selected from a single email.EnrchFoundContact– a contact in Creatio, identified by the data selected from the email. Stores a link to the Creatio contact andEnrchTextEntityof theContacttype.EnrchFoundAccount– stores information about the identified Creatio account (similar to theEnrchFoundContacttable).Activity– the fields added to the existing activity table show the connection between theEmailactivity and theEnrchEmailDataobjects with the current status of the information extraction process.EnrchProcessedData– contains information about processed data, either accepted or rejected by the user in the enrichment process.
-
The
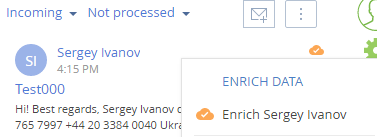
Email Mining Jobprocess notifies the user about the extraction process being finished. Messages are sent via the websocket channels to users who see the messages being processed in the communication panel. If the email contains information that may be used to enrich an associated contact, (or used to create a new contact altogether), the corresponding icon is displayed in the application interface in the upper right corner of the email .

An email like that will enable the user enrich or create a new contact of the system.
System settings
Enrichment system settings:
TextParsingService* – the address of theEnrichment Servicecloud–service for data enrichment. Filled automatically for on–demand users.CloudServicesAPIKey* – the key for accessing the cloud service API. Filled automatically for on–demand users.EmailMiningPackageSize– the number of emails processed at once. TheEmail Mining Jobprocess will process as many emails each time as it is specified in this system setting. Default value – 10.EmailMiningPeriodMin– the frequency (in minutes) of running theEmail Mining Jobprocess.
If the value of EmailMiningPeriodMin is less than or equal to zero, then the process will not be scheduled and the functionality will be disabled. To re–enable the process, set the value of the setting >=1, restart the application pool of the application, go to the login page and enter the application.
EmailMiningIdentificationActualPeriod– the period of relevance (in days) of contacts / accounts identification. If the specified period has expired and a new email is processed for the previously identified contact, the identification will be made again.
Identification sequence
Identifying contacts
- Search by full name.
- Search by name and last name.
- Search by email addresses. Only those email addresses that do not belong to free or temporary email services are taken into account.
- Search by phone. The search takes place only for the last digits of the contact's phone numbers.
If at any of the identification stages a data duplicate is detected, the identification process will be stopped.
Identifying accounts
- Search by the Name or Alternative name columns (case– insensitive).
- Search by web address.
- Search by email addresses. Only those email addresses that do not belong to free or temporary email services are taken into account. From the email address, the domain is allocated and the search for the communication facilities of the account for the filter starts with one of the following domain variants:
http://domain,https://domain,http://www.Domain,https://www.domain,www.domain,domain.
If at any of the identification stages a data duplicate is detected, the identification process will be stopped.
Hashing information
The information extracted from the email is hashed. As a result, in the EnrchTextEntity and EnrchEmailData tables, a hash value is written in the Hash field that uniquely identifies the given unit or set of extracted data in the system. This allows for two important improvements: resource savings when re–identifying contacts / accounts from a set of extracted information and grouping the information received for a contact.
Re–identification of contacts/accounts
For example, the system received an email with the signature of "John Smith Jr.", the telephone number "123–45–67" and the address "71 Pilgrim Avenue Chevy Chase, MD 20815." For the current data set, the system computed a hash of "Hash1" and recorded it in the Hash field of the EnrchEmailData table based on its contents. The identification of the contact revealed the contact "John Smith" in the system and recorded the result in the EnrchFoundContact table.
After a while the system received another email with a signature, which mentions the "John Smith Jr." contact with the same phone and address. The system calculated the same hash for the current data set – "Hash1", because the incoming hash data has not changed. Instead of creating new records in the EnrchEmailData and EnrchTextEntity tables and re–identifying this contact, the system found the previously created record in the Hash field of the EnrchEmailData table and wrote a reference to this record in the Activity table.
This process saves the amount of data stored and does not produce resource–intensive contact identification requests.
Grouping the highlighted information for a contact
Since each unit of the allocated information in EnrchTextEntity has a hash code based on its contents, when enriching the data of an existing contact, it becomes possible to use the information found in all the email in which it participated. When you select the data for enrichment, it is grouped by the Hash field and will not be duplicated.